Artificial intelligence can now help researchers analyze antibody sequences, predict structures, prioritize mutations, optimize candidate properties, and generate entirely new antibody sequences. These capabilities are changing what can be proposed computationally, but every proposed sequence raises the practical question: will the antibody actually work?
A candidate must be expressed, correctly assembled, and experimentally tested. It must bind the intended target while demonstrating suitable specificity, purity, stability, and other properties relevant to its intended application. Since generative models produce increasingly large candidate panels, the ability to convert sequences into standardized experimental data is an essential part of AI-driven antibody discovery.
AI is being applied across several stages of antibody research; for example, AI-assisted discovery can help identify patterns within experimental datasets and rank promising candidates. Meanwhile, AI-guided optimization generally begins with an existing antibody and proposes mutations intended to improve affinity, specificity, human-likeness, expression, or developability.
De novo design is more ambitious, as instead of modifying an experimentally validated antibody, the model generates a new antibody or binding molecule for a specified target or epitope. Recent studies suggest that de novo design may be moving away from extremely large, low-yield computational libraries toward smaller panels that can be evaluated experimentally.
Chai Discovery’s Chai-2 model, for example, was used to design antibodies or nanobodies against 52 targets. The researchers reported an overall experimental hit rate of approximately 16%, described as more than a 100-fold improvement over the success rates associated with earlier computational approaches. They have since developed the Chai-3 model, attracting significant industry interest, getting collaboration agreements with both Eli Lilly and Company and Pfizer and now being worth $1.3 billion.
Computational methods may be particularly useful for targets that are challenging for conventional antibody discovery.
Multipass membrane proteins, for example, often expose only limited extracellular regions. Their extracellular loops may be flexible, structurally dependent on the membrane environment, or highly conserved among related proteins. Nabla Bio has applied its Joint Atomic Modeling platform to membrane targets including Claudin-4, CXCR4, and CXCR7. They reported de novo antibodies with measurable affinity, epitope specificity, functional activity, and initial developability-related properties, and have now signed two deals with Takeda potentially worth $1 billion.
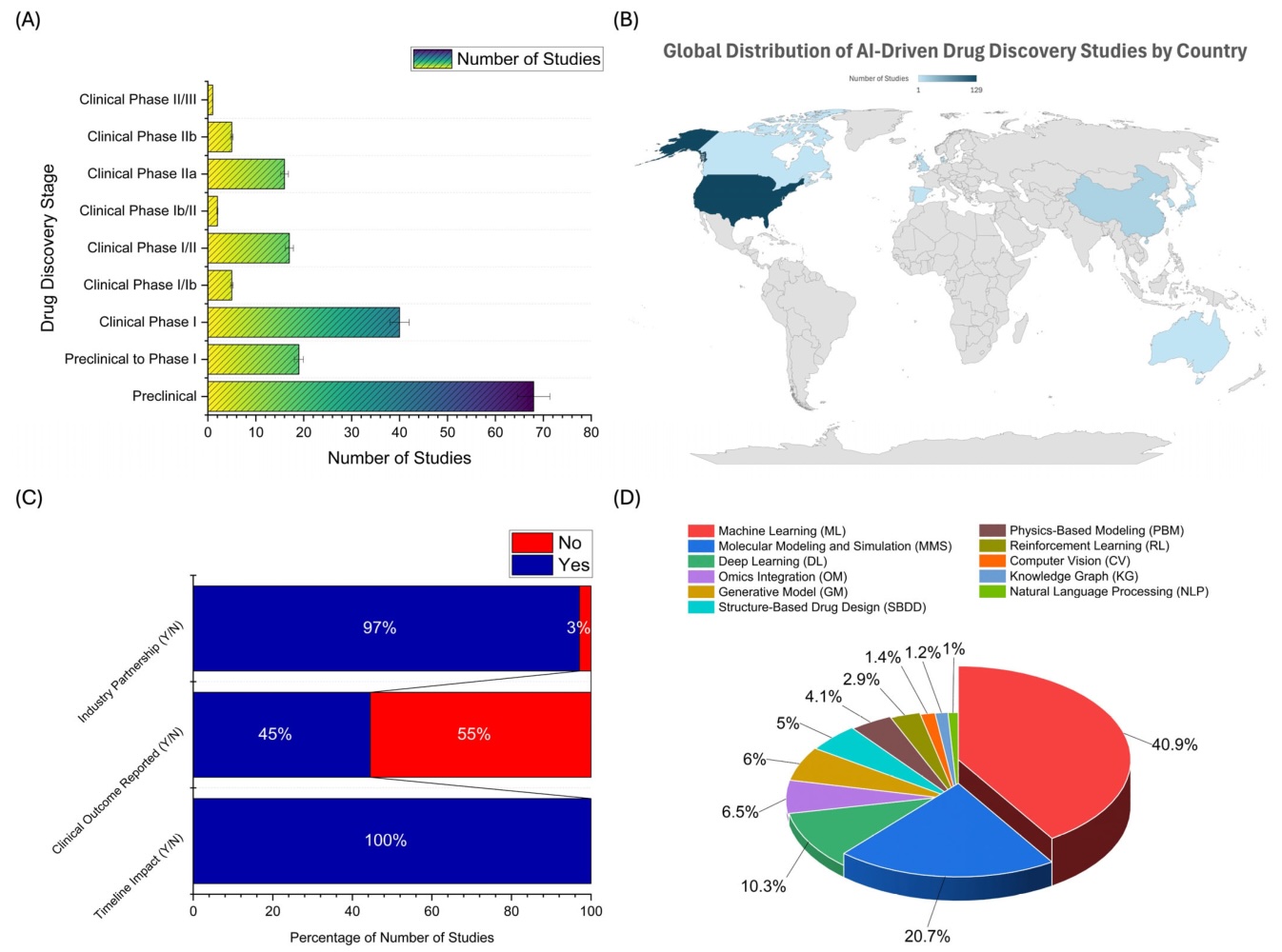
Commercial forecasts reflect strong expectations for AI-enabled antibody discovery. According to a ResearchAndMarkets analysis, the global AI-in-antibody-discovery market was valued at approximately $529.9 million in 2025 and is projected to reach $4.84 billion by 2035, representing a compound annual growth rate of 24.76%.
Just yesterday, Merck entered a multi-target discovery and licensing agreement with Protillion Biosciences that could generate up to $510 million. The collaboration will use machine learning with a continuous feedback loop of wet-lab measurements, generating large, quantitative antibody-binding datasets for drug discovery.
Absci has similarly built computational design and experimental screening into a closed-loop platform. Their Integrated Drug Creation platform uses generative AI to propose antibodies and then returns experimental results to subsequent modeling cycles. In fact, the first participants have been dosed in Phase 1/2a HEADLINE trial of AI-designed antibody ABS-201 for androgenetic alopecia.
The demand for scalable testing is also likely to extend beyond conventional monoclonal antibodies, with a report identifying more than 600 clinical trials for bispecific antibodies. More complex formats can introduce additional challenges related to chain pairing, assembly, expression, stability, valency, and functional assay design. This makes standardized experimental characterization even more important.
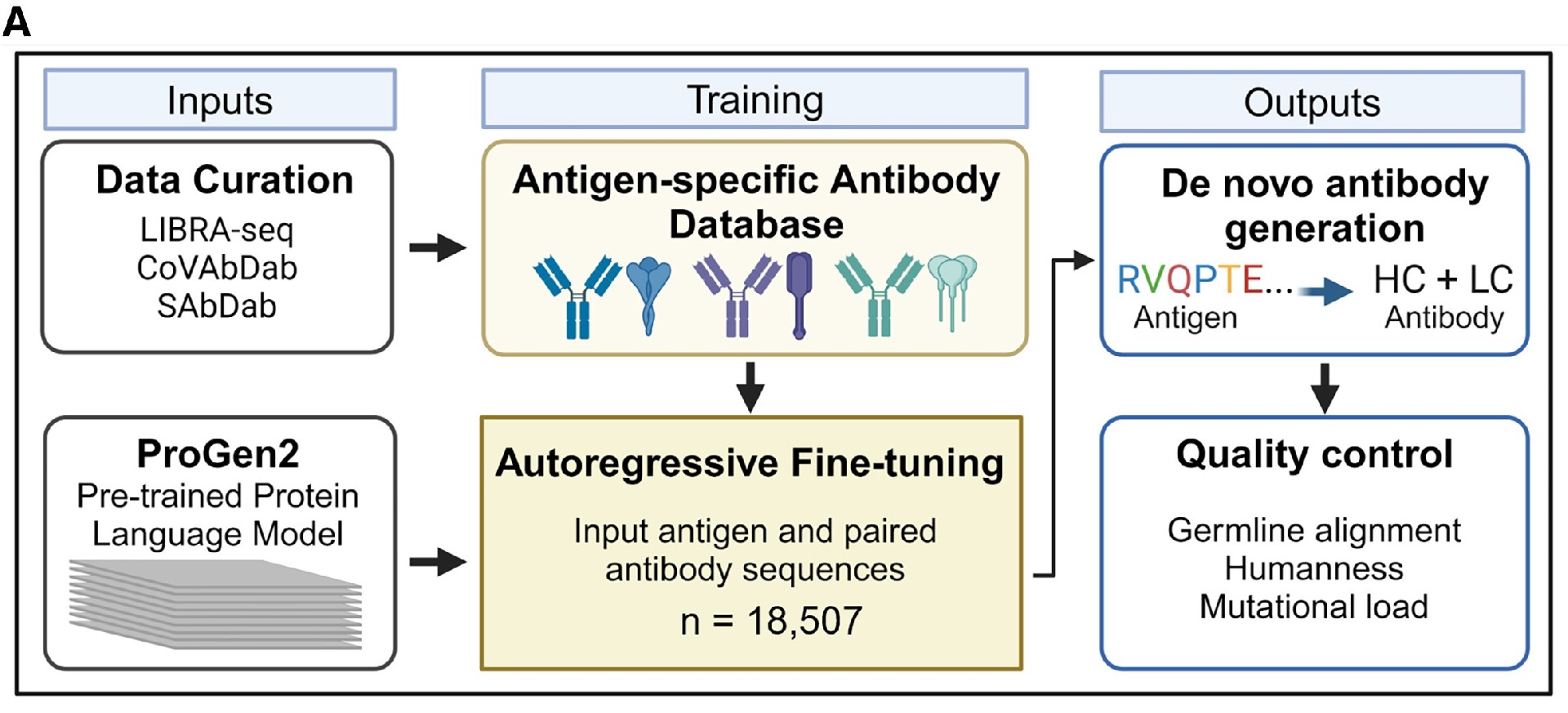
Machine-learning systems learn from the data used to train and evaluate them, but large antibody sequence databases do not always contain reliable heavy- and light-chain pairing, quantitative affinity measurements, epitope information, expression data, specificity results, assay metadata, or negative findings.
Data gathered across laboratories can also be difficult to compare, since differences in expression systems, antigen preparations, assay formats, reagent concentrations, controls, and processing methods may introduce variation unrelated to the antibody sequence itself.
Biointron developed RushData to support this transition from antibody sequences to AI/ML-ready datasets.
RushData combines 1-day CHO expression, rapid binding analysis, and early developability profiling. The platform can support panels of up to 3,000 antibodies in a batch, allowing large groups of computationally generated candidates to be produced and evaluated under comparable conditions.
The resulting data can help researchers determine which sequences express successfully, bind the intended target, maintain acceptable specificity and quality, and warrant further optimization. For AI and machine-learning teams, the data may also support model evaluation, active learning, fine-tuning, and subsequent design cycles.
To learn how RushData can support antibody design and optimization programs, visit Biointron’s website or contact info@biointron.com.
Biointron’s Q1 2026 Antibody Industry Trends report aims to explore the events a……
Degrader-antibody conjugates, or DACs, combine the targeting ability of antibodi……
Bispecific antibody-drug conjugates, or BsADCs, combines the payload-delivery fu……