AI is changing antibody discovery, but model performance depends on the quality of the experimental data used to train, validate, and refine predictions. Antibody researchers increasingly need more structured, comparable, and biologically meaningful datasets that link sequence design to expression, binding, and developability outcomes.
The gap between computational design and experimental validation can be bridged by high-throughput wet-lab characterization.
Antibody models begin with sequence information, but AI-designed candidates need confirmation of whether they express, bind, remain stable, and show early developability risks. Functional antibody behavior must be measured, including characteristics such as binding affinity, specificity, expression, aggregation risk, and other developability signals.
Experimental datasets help distinguish in silico designs from candidates with real-world potential. After all, algorithms are only as useful as the experimental data behind them.
Raw assay outputs are messy and not automatically AI-ready. Data becomes useful for machine learning when measurements are captured consistently, with standardized naming, units, assay conditions, and metadata.
Key points:
AI-ready datasets should use consistent sample IDs, antibody IDs, sequence IDs, target IDs, naming conventions, and readout formats.
Units and assay conditions should be standardized so results can be compared across candidates.
QC flags are important because models should not treat failed expression, poor-quality samples, or assay artifacts as equivalent to true biological outcomes.
With RushData, data is generated and delivered in a structure that supports downstream analysis.
The strongest datasets keep the relationship between the designed antibody sequence and every downstream experimental result. This allows teams to ask better questions, such as which sequence features correlate with expression, binding, hydrophobicity, or stability.
Each antibody candidate should be traceable from sequence to expression result to binding characterization to developability profile. Linked datasets allow researchers to compare successful and unsuccessful designs, with even negative results being useful because they help models learn.
AI antibody workflows benefit from multidimensional characterization, since a candidate with strong binding can still fail due to poor expression, aggregation, instability, or other developability liabilities.
Binding data helps rank candidates, but developability data helps avoid downstream attrition, with useful readouts including expression level, binding affinity or kinetics, purity, aggregation, thermal stability, hydrophobicity, charge-related behavior, and other early risk indicators. Multidimensional datasets are better suited for training models that optimize for more than affinity alone.
RushData is an example of a workflow designed to combine 1-day CHO expression, binding characterization, and developability profiling into structured outputs.
Machine learning depends on pattern recognition, which means dataset scale matters. However, scale only helps if the data is generated consistently enough to compare across many candidates.
The main idea is that thousands of candidates can create stronger learning loops than small, isolated datasets, as the end goal would be to feed results back into the design cycle for improving the next round of candidates.
Key points:
AI-ready data should help teams compare predicted vs. observed performance.
Experimental feedback can support model retraining, active learning, candidate triage, and design refinement.
The faster the feedback loop, the faster teams can move from sequence generation to improved designs.
This is where platforms like RushData speed up timelines from weeks to days to make model feedback loops more practical for AI-driven discovery teams.
An AI-ready antibody characterization dataset should include:
Antibody sequence information, including heavy and light chain pairing where applicable
Candidate/sample identifiers that remain consistent across production and assay steps
Expression data, ideally from a therapeutically relevant system such as CHO
Binding characterization data, including assay method and target context
Early developability readouts
Units, assay conditions, QC flags, and batch information
Structured output formats that can be imported into downstream databases, analytics workflows, or machine learning pipelines
AI antibody discovery will continue to improve, but its progress depends on experimental datasets that are structured and produced at scale. For companies designing antibodies computationally, RushData helps turn candidate sequences into structured experimental feedback through rapid CHO expression, binding characterization, and developability profiling, supporting faster decisions and more useful model iteration.
References:
Kim, J., McFee, M., Fang, Q., Abdin, O., & Kim, P. M. (2023). Computational and artificial intelligence-based methods for antibody development. Trends in Pharmacological Sciences, 44(3), 175–189. https://doi.org/10.1016/j.tips.2022.12.005
Antibody discovery has become increasingly sequence-rich. Display technologies, ……
Biointron, a leading contract research organization specializing in antibody dis……
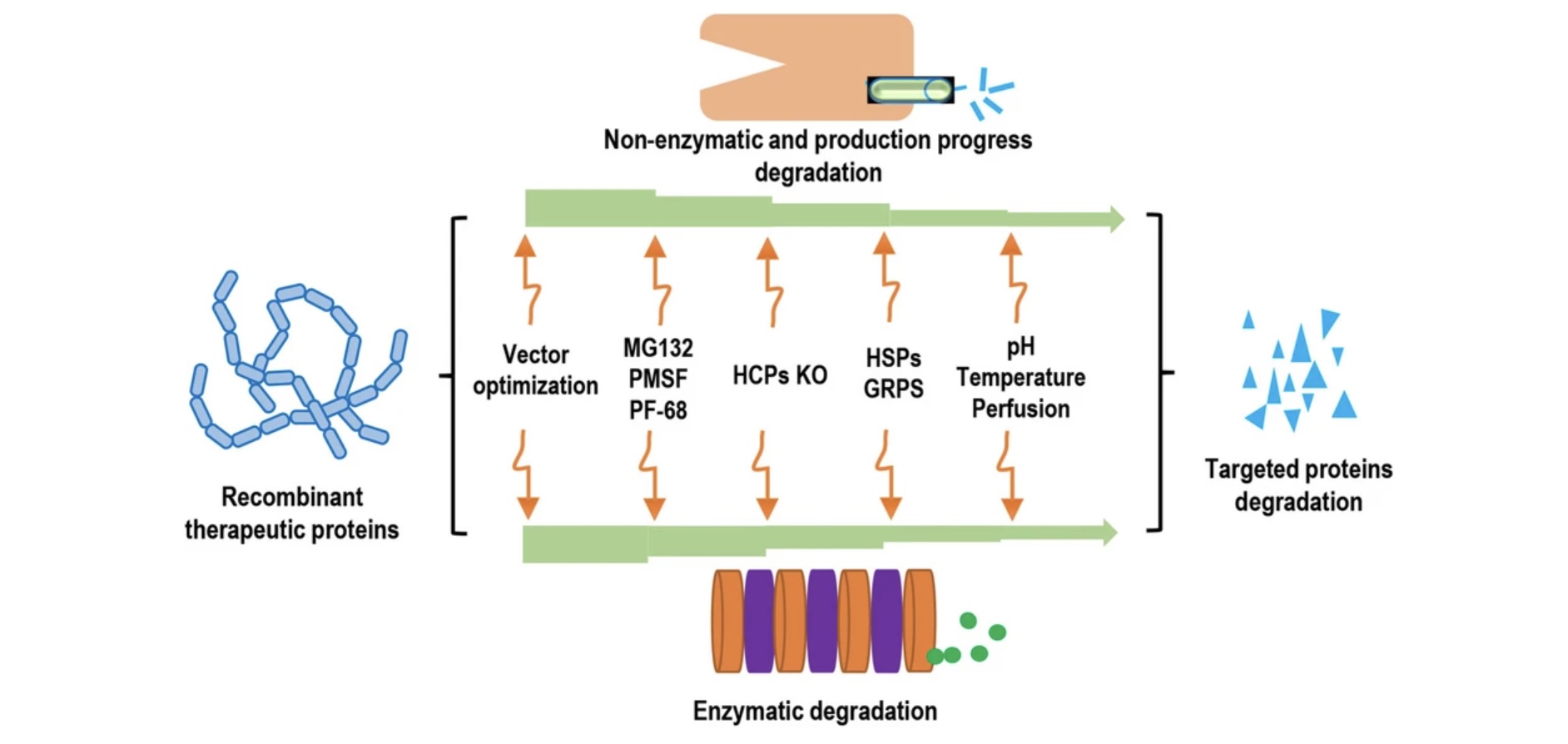
Post-translational modifications (PTMs) are chemical or structural changes made ……